Choosing a database for a system is always tricky. You need to consider too many variables, tradeoffs and system requirements. It gets even more complicated if the system already has a database. Migrating a live production database is risky and costly in both time and resources.
If the system already has a database & needs migration
Database migration will cost time and resources. Hence, before deciding, the first wise thing to do is to explore and then exhaust all possible options to optimize the existing setup.
There are a few definite points/scopes that we can focus on to optimize performance.
- First, we should explore the database configuration that's currently set in the existing system
- Oftentimes, it's the
working set memory sizethat's affecting performance. - When working with a legacy system, it's very common for this system to produce quite an amount of unused and old data. Reducing disk space usage by removing them can optimize quite a few queries. Seek times are reduced on smaller files, so it's important to review if the database needs compaction. FYI, compaction is the process of taking all the current revisions in the file and writing a new file with just the active documents, effectively deleting all old revisions.
- Garbage collection behavior can also play an instrumental role in particular data systems.
- Oftentimes, it's the
- If the database configurations seem perfect as they are, introducing a caching layer in front of the database is a very popular and common technique that many apply, especially in systems that require data in a predictable/repeating pattern.
- If the system is read-heavy, meaning a lot of data reads are taking place, a useful technique is to add database replicas. It helps to offload a number read loads if executed correctly.
- If the nature of the data of the system is siloed or isolated, sharding can be an acceptable solution too.
- Lastly, based on historical user data and system logs, we can assume how data fields are being calculated (and probably, displayed). Based on the understanding, some modules of system architecture tuning should be prioritized over migrating to a new database system.
If the system needs a new database
Before jumping into comparison whether to choose SQL or NoSQL, it's better if we spend a minute over the key points of SQL and NoSQL
SQL
- RDBMSs must exhibit four
ACIDproperties: Atomicity, Consistency, Isolation, Durability- SQL is recommended for systems where
- consistency is critical
- joins are important
- seamless & fast data backup & restore is essential
- Complex queries with joins are easy because the data is structured
- Example DBs:
MySQL,Postgres
- SQL is recommended for systems where
NoSQL
- NoSQL adheres to the CAP theorem, and 2 of the 3 properties can be guaranteed:
- Consistency,
- Availability and
- Partition Tolerance
- NoSQL is recommended for systems where
- Big data & scalability
- Flexibility of unstructured data that don't need joins
- Repeating/Predictable query patterns with partition & sort keys are easy because every data should have an ID
- Example DBs & their data storage models
- Document/JSON:
MongoDB(multi-platform applications on web, mobile & social networks) - Key-value pairs:
Redis(caching, i.e. Memcached) - Wide-column/tables with rows and dynamic columns:
Cassandra(large amounts of data with predictable query patterns, i.e. inventory management system) - Graph/nodes & edges:
Neo4j(fraud detection & analytics, recommendation engine, social media/network graphs) - Search/search engine daemon:
OpenSearch(application search, log analytics, data observability)
- Document/JSON:
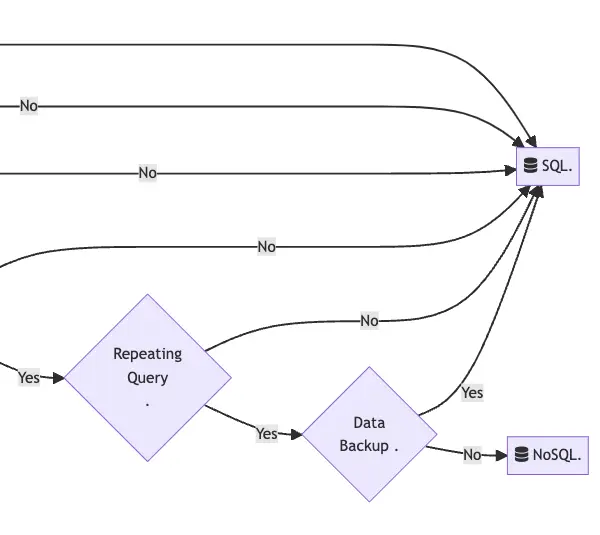
SQL vs NOSQL - Decision Tree
Here's an opinionated decision tree that I used to follow based on the resources and learnings I had in my first few professional years:
Loading graph...
Expand this section to view the vertical version of this decision tree
Loading graph...
Resources/References
Readings for the ones who want to dive deeper:


